Directions
-

KAIST 전산학부 오태현 교수 연구실, ACL 2026 Main 및 구두발표 채택
전기및전자공학부 이정목 박사과정, 오태현 교수 지도 아래 연구 수행 실세계 웃음 이해 위한 멀티모달 데이터셋·추론 프레임워크 제안 KAIST 전산학부 오태현 교수 연구실에서 수행한 연구가 자연어처리 분야 최고 권위
-

KAIST 오태현 교수 연구팀, 시각·언어 AI 모델의 이해 능력 높이는 기술 개발… CV..
KAIST 오태현 교수 연구팀이 이미지와 글을 함께 처리하는 인공지능 모델의 이해 능력을 높이는 새로운 기술을 개발했다. 연구팀의 논문 “Aligning What Vision-Language Models See and Pe
-

KAIST 오태현 교수 연구팀, 멀티모달 AI의 한계 밝히는 연구로 CVPR 2026 채택
음성과 영상 정보를 함께 이해하는 AI의 오류를 체계적으로 분석 신뢰할 수 있는 멀티모달 AI 개발에 새 기준 제시 KAIST 전산학부 오태현 교수 연구팀(AMI Lab)의 논문 “SVHalluc: Benchmark
-

KAIST 김대영 교수 연구팀, 최신 비전언어모델의 시각적 편향 드러낸 ‘VLMBias’ ..
KAIST 김대영 교수 연구팀이 최신 비전언어모델(Vision-Language Model, VLM)이 실제 이미지 정보를 충분히 보지 못하고, 학습 과정에서 얻은 사전 지식에 의존해 잘못된 답을 내는 현상을 체계적으로 분석한 연구 결
-

KAIST 한준 교수 연구팀, 스마트폰으로 숨겨진 카메라 탐지하는 ‘SweepLED’ 기술..
KAIST 한준 교수 연구팀이 스마트폰만으로 숙박시설 등에 숨겨진 몰래카메라를 탐지할 수 있는 기술 ‘SweepLED’를 개발했다. 이 기술은 LED 조명을 다양한 각도로 순차적으로 비추는 방식으로 렌즈 특유의
-

KAIST 이의진 교수 연구팀, 데이터 기반 스트레스 관리 기술의 설계 원리 체계적으로 정..
KAIST 이의진 교수 연구팀이 데이터 기반 스트레스 관리 기술의 연구 동향을 체계적으로 분석한 리뷰 연구를 발표했다. 해당 연구는 웨어러블 센서와 자가보고를 활용한 스트레스 추적 기술이 실제 개입 설계와 어떻게 연결되고 평가되어 왔
-

KAIST Joseph Seering 교수 연구팀, 분담형 뉴스 담론 시스템으로 집단 공론..
KAIST Joseph Seering 교수 연구팀은 온라인 뉴스 공간에서 보다 연결되고 균형 잡힌 공론장을 형성할 수 있는 새로운 담론 시스템을 제안했다. 연구팀은 기존 논의 환경을 구조화된 단위로 재구성하고, 사용자가 기능적 역할을
-

KAIST 성민혁 교수 연구팀, 고품질 PBR 텍스처 생성을 위한 ‘Material Lat..
KAIST 성민혁 교수 연구팀이 3D 메쉬에 적용 가능한 고품질 PBR(Physically Based Rendering) 텍스처를 생성하는 새로운 생성 프레임워크 ‘MatLat(Material Latent Space)&rs
-

KAIST 오태현 교수 연구팀, 단일 영상으로 고품질 3D 얼굴 아바타 생성 기술 개발
KAIST 오태현 교수 연구팀이 단일 카메라 영상만으로도 사실적이고 애니메이션 가능한 3D 얼굴 아바타를 생성하는 기술을 개발했다. 최근 IEEE Conference on Computer Vision and Pattern Recogn
-

KAIST 박노성 교수 연구팀, Mamba2를 그래프 신호 처리로 재해석한 경량 시퀀스 모..
KAIST 박노성 교수 연구진이 상태공간모델(SSM) 기반 시퀀스 모델인 Mamba2를 그래프 신호 처리(Graph Signal Processing, GSP) 관점에서 재해석하고, 이를 바탕으로 효율성과 해석 가능성을 동시에 높인 새
-

KAIST 김주호·오혜연 교수 연구팀, 실제 중학교 교실에서 LLM 글쓰기 지원의 한계와 ..
실시간 K-12 영어 수업에서 인간–AI 협업의 새로운 설계 과제 제시 KAIST 김주호·오혜연 교수 연구팀이 대규모 언어모델(LLM)을 활용한 글쓰기 지원 도구가 실제 K-12 영어 수업 현장에서 학생과
-

김민혁 교수 연구팀, 편광광의 복잡한 표현 문제를 해결하는 새로운 방법 S2L2 개발
KAIST 전산학부 김민혁 교수 연구팀이 편광광을 보다 안정적이고 일관되게 표현할 수 있는 새로운 방법 S2L2를 개발했다. 이 연구는 컴퓨터 그래픽스 분야 최고 권위 학술지인 ACM Transactions on Graphics(TO
-

김민수 교수 연구팀, 중앙집중식 STGNN을 연합학습으로 확장하는 범용 프레임워크 FedS..
KAIST 전산학부 김민수 교수 연구팀이 중앙집중식 Spatio-Temporal Graph Neural Network(STGNN)를 연합학습(Federated Learning) 환경으로 손쉽게 확장할 수 있는 범용 프레임워크 FedS
-

KAIST 박종철 교수 연구팀, 저자원 언어 ‘티그리냐’ 온라인 혐오 발화 분석 위한 대..
KAIST 전산학부 박종철 교수 연구팀이 아프리카 지역의 저자원 언어인 티그리냐(Tigrinya)에서 온라인 혐오·모욕 발화를 감지하기 위한 최초의 대규모 멀티태스크 벤치마크 데이터셋 ‘TiALD(Tigriny
-

KAIST 전산학부 오혜연 교수 연구팀, 고전 중국어 기반 교차언어 전이 가설을 재검증한 ..
KAIST 전산학부 오혜연 교수 연구팀이 동아시아 한자문화권 고문헌 처리에서 널리 사용돼 온 고전 중국어(문언문, Classical Chinese) 자원이 한문(Hanja) 모델 성능을 높인다는 기존 가설을 실증적으로 재검증한 연구를
-

KAIST 안성진 교수 연구팀 NeurIPS 2025 Spotlight 선정, 100배 빠..
KAIST 전산학부 안성진 교수 연구팀이 확산 기반 플래닝(diffusion-based planning)의 계산 효율을 획기적으로 개선한 인공지능(AI) 기술 ‘Fast-MCTD’를 개발했다. 이 연구는 세계적
-

사용자 의도 더 정확히 반영하는 생성 AI ‘Ψ-Sampler’, KAIST 성민혁 교수 ..
KAIST 전산학부 성민혁 교수 연구팀이 생성 모델이 사용자 조건을 더욱 정확하게 반영하도록 돕는 새로운 인공지능(AI) 기술 ‘Ψ-Sampler’를 개발했다. 이 연구는 세계적 기계학습 학회 NeurIP
-

KAIST 김현우 교수 연구팀 ICCV 2025 Highlight 논문 선정, 영상과 문장..
KAIST 전산학부 김현우 교수 연구팀이 Meta와 함께, 영상과 문장을 더 정확하게 연결해주는 새로운 인공지능(AI) 기술을 개발했다. 이 연구는 컴퓨터 비전 분야의 세계적인 학회 ICCV 2025에서 Highlight 논문으로 선
-

KAIS 이기혁 교수 연구팀 UIST 2025 Honorable Mention Award ..
KAIST 전산학부 HCI 연구실의 이기혁 교수 연구팀이 가상현실(VR)에서 새로운 조작 방식을 가능하게 하는 ‘TwinSpin’ 컨트롤러를 개발했다. 이 연구는 세계적 인터페이스 학회 UIST 2025에서 발표
-

KAIST 전산학부, 군중 밀집 사고 예측하는 AI 기술 개발
- 정점·간선 흐름 동시에 학습해 예측 정확도 76% 향상… 세계적 AI 학회 KDD 2025 발표 예정 - KAIST 전산학부 이재길 교수 연구팀이 군중 밀집 사고를 사전에 예측할 수 있는 인공지능(A
-

실세계 인공지능 훈련 비용 최소화 기술 및 감염병 관리 문제 응용
책임교수: 이재길 교수 주요 성과: IEEE TNNLS 논문(약 1,200회 인용), NeurIPS/ICML 다수 논문 게재, 미국 및 한국 특허 등록 연구 개요 실세계 인공지능 학습에는 레이블 오류, 레이블 부족, 데이
-

거대언어모델(LLM) 서빙 가속을 위한 이기종 AI 반도체 기반 클라우드 시스템 연구
책임교수: 박종세 교수 참여연구자: 허구슬, 이상엽, 조재홍, 최현민, 이상현, 김민수, 함형규(POSTECH), 김광선(POSTECH), Divya Mahajan (Georgia Institute of Technology)
-

감정노동자 정신건강 돕는 AI 개발
"감정노동자 정신건강 돕는 AI 개발" 콜센터 상담사의 스트레스 수준을 분석해 정신건강을 보호하는 인공지능(AI) 기술이 개발됐다. KAIST 이의진 교수 연구팀은 중앙대, 미국 애크런대와 협력해 감정노동
-

초거대 언어모델 추론 서비스 제공을 위한 HW/SW 공동 시뮬레이션 인프라(LLMServi..
전산학부 박종세 교수 연구팀, 컴퓨터 시스템 워크로드 특성화 분야에서 세계적으로 권위 있는 학술대회인 IISWC 2024에‘최우수 논문상’,‘최우수 연구 기록물상 ’ 동시 수상 LLM 추
-

지금 당신의 마음 건강은 어떠한가요?
< 전산학부 이의진 교수 연구팀 > 최근 빠른 고령화 및 출산율 감소 등으로 1인 가구가 급속하게 증가하면서, 1인 가구의 정신건강 문제에 대한 관심도 함께 높아지고 있다. 서울시가 실시한 1인 가구 실태조사에 따르면
-

카이스트가 개발한 '이 기술'…무선신호 없는 실내서도 치매환자 찾아낸다
출처 : 카이스트가 개발한 '이 기술'…무선신호 없는 실내서도 치매환자 찾아낸다 출처 : SBS 뉴스 원본 링크 : https://news.sbs.co.kr/news/endPage.do?news_id=N
-

KAIST, 美 국방부가 주목한 C-러스트 기술 선도...˝C 코드를 러스트언어로 자동 번..
출처: https://www.aitimes.kr/news/articleView.html?idxno=31948 KAIST 전산학부장 류석영 교수 컴퓨터 시스템을 작동시키기 위해서는 소프트웨어를 작성해야 하는데
-

지속적인 학습 능력을 갖춘 인공지능 기술 개발
KAIST, 변화에 민감한 사용자도 맞춰주는 인공지능 기술 개발 - 이재길 교수팀, 다양한 데이터 변화 정도에 적응하는 연속 학습 기술 개발 - 지난 7월 최고권위 국제학술대회 ‘국제머신러닝학회(ICML) 2024&
-

뇌졸중 환자 손 재활 돕는다…KAIST, AI 기반 고정확도 손동작 의도파악 기술 구현
KAIST 기술을 이용해 물건을 집는 손자세를 보조하는 모습. 한국과학기술원(KAIST) 연구진이 뇌졸중 환자의 손 재활 훈련을 돕는 인공지능(AI) 기술을 구현했다. 환자 의도를 감지해 원하는 자세를 취하는 것에 도움을 준다.
-

자바스크립트 안정성을 책임지다
< 전산학부 류석영 교수 연구팀 > 전 세계에서 가장 널리 사용되는 프로그래밍 언어 중 하나인 자바스크립트*는 컴퓨터 뿐 아니라 스마트폰, 스마트시계 등 다양한 기기에서 동작하기 때문에, 자바스크립트 실행기를 올바르게
-

카이스트, 메타버스 시대에 필요한 GPU 대규모 출력 데이터 신속처리 기술 개발
출처 : 뉴스프리존(https://www.newsfreezone.co.kr) 카이스트, 메타버스 시대에 필요한 GPU 대규모 출력 데이터 신속처리 기술 개발 한국과학기술원(KAIST, 총장 이광형) 전산학부 김민수
-

FPS 게임에서의 에임봇 탐지 인공지능
BotScreen은 신뢰성있는 실행 환경을 사용하여 확장가능하고 신뢰할 수 있는 방식으로 FPS 게임에서 에임봇을 감지할 수 있는 완전한 분산 인공지능 시스템이다. 본 연구팀은 USENIX Security Symposium에서 Dis
-

동기화된 공동 확산 기법을 통한 일관된 몽타주
사전 훈련된 이미지 확산 모델의 놀라운 능력은 고정 크기의 이미지를 생성하는 데뿐만 아니라 파노라마를 만드는 데에도 활용되어 왔습니다. 그러나 여러 이미지의 단순한 스티칭은 종종 보이는 줄무늬를 유발합니다. 이 한계를 극복하기 위해
-

SegFuzz: 쓰레드 인터리빙 분할 기법을 활용한 커널의 동시성 버그 퍼징
커널 동시성 버그 (kernel concurrency bug)를 탐지하는 일은 매우 어려운 일이다. 이는 비동시성 버그와 다르게, 커널 동시성 버그를 식별하려면 여러 스레드 간의 인터리빙에 대한 분석이 필요하기 때문이다. 그러나 스레
-

낮은 언어자원의 한계를 극복하여 이해도가 높은 답변이 가능하게 하는 티그리냐 질문-답변..
우리 전산학부의 Fitsum Gaim, 양원석, 박한철 (지도교수: 박종철) 연구팀이 2023년 7월 9일~13일 토론토에서 열린 ACL 2023 에서 Outstanding Paper Award를 수상했다. 연구팀의 획기적인 논문인
-

KAIST, 그래픽 연산 장치 '대규모 출력데이터 난제' 해결
전산학부 김민수 교수님 연구팀의 "KAIST, 그래픽 연산 장치 '대규모 출력데이터 난제' 해결" 관련 기사입니다. 김민수 교수팀 "가정용으로도 대규모 출력 빠르게 가능"
-

Universal Few-shot Learning of Dense Prediction Ta..
KAIST(총장 이광형)는 전산학부 홍승훈 교수가 이끄는 연구팀이 지난 5월 1일부터 5월 5일에 열린 기계학습 분야의 최우수 국제학술대회인 ‘표현 학습 국제 학회 2023(International Conference on
-
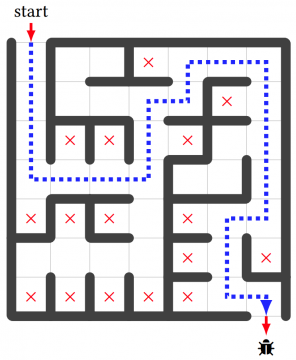
소프트웨어 버그 찾기를 시각화할 수 있는 취약 프로그램 합성기술
전산학부 차상길 교수 연구팀이 소프트웨어 버그를 시각적으로 표현할 수 있는 취약 프로그램 합성기술을 개발했다. 해당 논문은 소프트웨어 공학 최우수 학술대회인 ASE 2022에 지난 2022년 10월에 발표되었으며, 차상길 교수 연구팀
-

A Unique Experiment That Could Make Social Media B..
Sources https://www.wired.com/story/platforms-engagement-research-meta/ Prof. Miyoung Cha(KAIST School of Computing) and Sungw
-
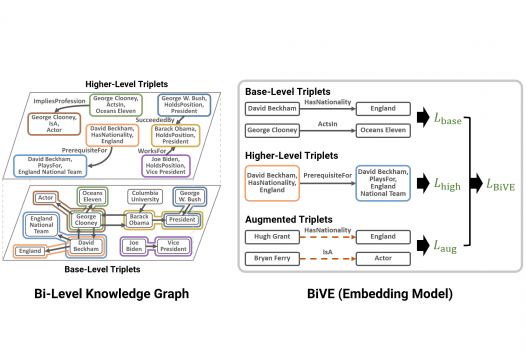
Learning Representations of Bi-Level Knowledge Gra..
KAIST 전산학부 황지영 교수 연구진이 2023년 2월 7일~14일 미국 워싱턴 D.C.에서 열린 인공지능 분야 Top-tier 국제 학회인 AAAI Conference on Artificial Intelligence (AAAI 2


